How to speed up the Rust compiler in April 2022
In my last post I introduced the Compiler performance roadmap for 2022. Let’s see how things are progressing. Normally in these posts I mostly write about my own work, but there is enough interesting stuff going on that I will mention work done by other people as well.
Declarative macro expansion
One item on the roadmap is declarative macro expansion. It had (surprisingly) been found to dominate compile times of numerous crates, and is under-represented in the benchmark suite. We made progress on this within the compiler and elsewhere.
Compiler
The part of the compiler that does declarative macro matching is quite old. Much of the code predated Rust 1.0, and it was the kind of code that people do their best to avoid touching. Time for some Type 2 fun.
I made a lot of PRs to improve this code. There were some good performance wins, combined with many basic refactorings to make the code nicer and easier to understand. Things like:
- improving formatting;
- moving code into separate functions;
- reordering code;
- renaming things;
- adding assertions to make invariants explicit;
- improving and simplifying types;
- improving consistency;
- removing redundant data;
- and generally simplifying things whenever possible.
In the rest of this section, performance improvements are for instructions
counts of check full builds, which is rustc-perf’s name for “a cargo check
build with incremental compilation disabled”. This is a good baseline for
changes affecting the compiler front-end. The wins I mention are not just on
the usual rustc-perf benchmarks, but also a selection of crates that use
declarative macros heavily.
Here are the PRs.
- #94547 (5 commits, filed March 3): Basic refactorings.
- #94693 (2 commits, filed March 7): This PR inlines some hot parser functions called from the macro expansion code, for up to 4% wins.
- #94798 (6 commits, filed March 10): Basic refactorings.
- #95067 (6 commits, filed March 18): Basic refactorings.
- #95159 (7 commits, filed March 21): Basic refactorings, plus an improvement in an important data structure that gave up to 11% wins.
- #95259 (4 commits, filed March 24): More data representation tweaks, giving up to 7% wins.
- #95301 (1 commit, filed
March 25). A refactoring that simplified the
Nonterminaltype. - #95425 (6 commits, filed March 29): Basic refactorings, plus a big overhaul of how metavariable matches are represented, giving up to 17% wins.
- #95509 (5 commits, filed March 31): More refactorings and simplifications, for some sub-1% wins.
- #95555 (2 commits, filed April 1): A new matcher representation that makes the code simpler, more concise, and gave up to 10% wins. Yay! This one felt really good.
- #95669 (3 commits, filed Apr 5): A change to compute the new matcher representation once per macro rule rather than once per macro rule invocation, giving up to 2% wins.
- #95715 (1 commit, filed
April 6): Shrank
Nonterminalfor some small memory usage wins. - #95797 (1 commit, filed April 8): Reverted a representation change from #95159 that was no longer necessary after #95555.
- #95794 (3 commits, filed April 8): Basic refactorings.
- #95928 (5 commits, filed April 11): Avoided some cloning, giving up to 3% wins.
Phew! Many thanks to @petrochenkov for reviewing all these PRs.
Here are the improvements across the macro-heavy crates.
| Benchmark | % Change |
|---|---|
| async-std-1.10.0 | -41.85% |
| time-macros-0.2.3 | -30.40% |
| yansi-0.5.0 | -26.27% |
| ctor-0.1.21 | -8.09% |
| scroll_derive-0.11.0 | -7.76% |
| num-derive-0.3.3 | -7.22% |
| funty-2.0.0 | -6.64% |
| enum-as-inner-0.4.0 | -6.54% |
| stdweb-derive-0.5.3 | -6.46% |
| pest_generator-2.1.3 | -6.50% |
| vsdb_derive-0.21.1 | -6.38% |
| tonic-build-0.7.0 | -6.38% |
| wasm-bindgen-backend-0.2.79 | -6.09% |
| futures-macro-0.3.19 | -5.97% |
| mockall_derive-0.11.0 | -5.91% |
| wayland-scanner-0.29.4 | -5.68% |
| clap_derive-3.1.7 | -5.63% |
| serde_derive-1.0.136 | -5.60% |
| prost-derive-0.10.0 | -5.52% |
| diesel_derives-1.4.1 | -5.39% |
| ref-cast-impl-1.0.6 | -4.99% |
| pyo3-macros-backend-0.16.3 | -4.93% |
| html5ever-0.26.0 | -4.45% |
| enumflags2_derive-0.7.4 | -4.29% |
| futures-lite-1.12.0 | -3.25% |
| nix-0.23.1 | -3.02% |
There are a few additional measurements I’m particularly happy with.
- The
MatcherPostype is at the heart of macro matching. Before I started, it had two lifetime parameters, 10 fields and took up 192 bytes. It now has zero lifetime parameters, two fields and takes up 16 bytes. - When doing a
check fullbuild ofasync-std-1.10.0, the compiler used to do 23.9 million heap allocations. It now does 2.5 million, and most of them are unrelated to macro expansion. Three cheers for DHAT! - The file
macro_parser.rsused to have 766 lines. It now has 718 lines.
Third-party crates
Although the compiler improvements are nice, some declarative macros remain expensive, and rewriting or removing them altogether from third-party crates is worthwhile.
async-std
async-std was #1 on the list of macro-heavy crates.
#1005: In this PR I
optimized the extension_trait! macro within this crate by removing some
unused rules and moving push-down accumulator state to the end of rules.
#1006: I then learned that
the extension_trait! macro could be removed altogether, which I did in this
PR.
These two changes had roughly equal performance effects, and combined they
reduced the check full build time of this crate by more than 50%. They are
present in the 1.11.0 release. Thanks to
@yoshuawuyts for his help on these changes.
time-macros
time-macros was #2 on the list of macro-heavy crates.
#453: In this PR I sped up the
quote_internal! macro within this crate by moving its accumulator to the end,
which avoids lots of wasted matching when a rule fails. This halved the time
for check full builds.
This change is present in the 0.3.9 release, along with two other internal improvements to that macro (one, two) by @jhpratt.
yansi
yansi was #3 on the list of macro-heavy crates.
#36: In this PR I removed the
docify! macro from yansi, reducing check full times by 60%.
This change is present in the 0.5.1 release, which is also the first new release in three years! Thanks to @SergioBenitez for his help on these changes.
quote
quote is a widely used crate. Of the 26 crates from the
analysis most affected by
macro expansion, 18 of them were due to use of quote::quote!. So this macro
is worth optimizing as much as possible.
#209: In this PR I reordered the
many rules in the quote_token! and quote_token_spanned! macros so the most
commonly used ones were first, for up to 6% wins across those 18 crates.
#210: In this PR
@lqd reordered arguments within rules in the
quote_token! and quote_token_spanned! macros so that less work was done on
rules that failed to match, for up to 2% wins across those same crates.
#211: quote! uses an advanced
and non-obvious technique that makes it act like a TT muncher but with better
worst-case performance and no need to modify the recursion_limit. In this PR
I documented the code to explain how it works. Some people will run screaming,
but for those who like tricky macros this
comment
will be of great interest.
#217: In this PR I added rules to
optimize the cases where quote! is passed only one or two token trees, for
up to 12% wins across those same crates.
These changes are present in the 1.0.18 release of quote. Thanks to
@dtolnay for his help on these changes.
Here are the improvements across the aforementioned crates that use quote.
| Benchmark | % Change |
|---|---|
| ctor-0.1.21 | -12.23% |
| enum-as-inner-0.4.0 | -12.02% |
| num-derive-0.3.3 | -10.81% |
| pest_generator-2.1.3 | -10.72% |
| wasm-bindgen-backend-0.2.79 | -9.03% |
| clap_derive-3.1.7 | -8.98% |
| tonic-build-0.7.0 | -8.80% |
| scroll_derive-0.11.0 | -8.10% |
| wayland-scanner-0.29.4 | -7.66% |
| enumflags2_derive-0.7.4 | -7.29% |
| pyo3-macros-backend-0.16.3 | -6.95% |
| stdweb-derive-0.5.3 | -6.80% |
| prost-derive-0.10.0 | -6.60% |
| mockall_derive-0.11.0 | -6.45% |
| diesel_derives-1.4.1 | -6.38% |
| vsdb_derive-0.21.1 | -6.10% |
| ref-cast-impl-1.0.6 | -6.09% |
| futures-macro-0.3.19 | -5.58% |
Note that these are in addition to the improvements from the earlier table.
E.g. ctor-0.1.21 will get an 8% reduction from compiler improvements, and an
additional 12% reduction from quote improvements.
Documentation
The Little Book of Rust Macros is an excellent guide to Rust macros. I read it when I first started looking at declarative macro expansion and learned a lot.
#58: In this PR I added advice about all the performance pitfalls of declarative macros I learned while doing this work. In particular, the fact that TT munchers and push-down accumulation macros are inherently quadratic! This is something that I didn’t know until recently, and I suspect many other people also don’t know.
Benchmarking
#1290: In this PR I added
a new benchmark called tt-muncher to rustc-perf. This benchmark is
representative of many crates that use declarative macros heavily.
Reflections
I have now reached the end of this work on macro expansion. I got a lot done in
six weeks, which is pleasing, and I know it looks impressive when written down
in a big list. But I want to emphasise that it mostly didn’t feel this like
that while I was doing it. I didn’t set out to rewrite 75% of
macro_parser.rs, even though that’s what happened in the end.
If you look closely at the PRs for the compiler, they were slow to start with, and the early ones were all basic refactorings. My first performance win in the macro expansion code wasn’t until March 18, nineteen days after I started looking at the macro expansion code. (And note that I work full-time on the compiler.) I spent plenty of time in the first three weeks just staring at the code, taking notes, and trying things, many of which didn’t work, or did work but were unsatisfactory for one reason or another. Progress didn’t speed up until the second half of the six weeks.
In fact, during those first three weeks there were times when I thought I wouldn’t get any macro expansion performance wins in the compiler. That’s why I switched to working on some of the third-party crates, just to get some wins there. After that I switched back to working on the compiler, mostly because my spidey senses were still tingling about both the readability and the performance of the code. In particular, DHAT profiles showed that the code was doing huge numbers of heap allocations, which is a pet peeve of mine.
Along the way I had to undo some optimizations I had added to this code a
couple of years ago. Those optimizations turned out to be useful for one kind
of expensive macro (with many rules but no metavariables) present in the
html5ever benchmark. But such macros aren’t common in practice, and these
optimizations were unhelpful for more typical expensive macros, which are
recursive, have fewer rules, and use metavariables. This shows the value of a
good benchmark suite.
I made some missteps, too. Most notably, I caused a P-critical
bug when I removed a code path
that I mistakenly thought was impossible, which briefly prevented
ring from compiling with Nightly. (Apologies
to everyone who was affected!) Interestingly, my mistake unintentionally
exposed a possible bug: the compiler currently ignores doc comments in a
matcher, which is arguably the wrong thing to
do.
But enough real code depends on this behaviour that it can’t be changed without
some care.
One lesson: never underestimate the impact of many small improvements. Also, never underestimate the usefulness of refactorings for learning how code works, and for enabling bigger improvements. Any time I want to dive deep into a new piece of code, I start by doing refactorings. For this code I made over 50 commits, and around 90% of them were refactorings that didn’t improve performance. But I couldn’t have made the 10% that did improve performance without the other 90%. These changes don’t just help me. Other people will find this code easier to read and modify now.
Finally, note that for all this effort, I’ve only improved the constant factors for declarative macro expansion. Many recursive macros are still inherently quadratic. It would be nice to find a way to eliminate this by doing something smarter to avoid reparsing token streams that are repeatedly captured by macro metavariables. If anyone wants to work on this, I’m happy to provide pointers on where to start.
Alright, enough about macros. Time for something else.
Better benchmarks
An entire section of the roadmap is about better benchmarks in rustc-perf, and good progress has been made there.
#1181: Not all the benchmarks in the benchmark suite are equally important. In particular, many are synthetic stress tests that are useful for detecting regressions, but are not as important as popular, real-world crates. In this PR, new contributor @Kobzol split the benchmarks into “primary” and “secondary” categories, which required changes to the benchmark harness, the database, and the website for viewing results. This makes looking at performance results much nicer, which is great for those of us who do that a lot.
Once the primary/secondary split was done, we were able to undertake the large
task of updating all the real-world crates in the benchmark suite to the
latest versions. This is a good thing, because many of the versions were four
or five years old. (To give you one example, we upgraded the syn crate from
v0.11.11 to v1.0.89!) This task was
shared by me, @Kobzol, @lqd,
and @rylev. And thanks to
@jdm for making a new html5ever release to help
with this.
For those who care about data continuity, never fear: the handful of “stable” benchmarks used for the perf dashboard have been kept, though they are no longer run on every commit. This means our longest ongoing record of compiler performance will continue, albeit on benchmarks that are now quite dated.
Finally, @rylev, @Kobzol, and new contributor @miwig have made many improvements to the results website and automated reports that are posted to GitHub PRs after CI runs. These are not of general interest to Rust users, but are useful to those of us working on compiler performance.
Miscellaneous
#94704, #95724: In these PRs @Kobzol twice updated the the benchmarks used for profile-guided optimization of rustc releases, for wins across numerous benchmarks of up to 5% in the first PR and 2% in the second PR. Importantly, most of these improvements were on debug and release builds of the largest real-world benchmarks.
#94776: In this PR, new
contributor @martingms optmized the
ascii::escape_default function, for wins of up to 12% on the deunicode
crate.
#95473: In this PR, @lqd started adding some machinery for tracking proc macro executions when doing self-profiling. This will hopefully be the start of some useful performance diagnosis tooling.
#94597,
#94690,
#94733: In these PRs I updated
the interning of ConstAllocation, Layout, and AdtDef, respectively, for
wins on a few benchmarks of up to 1%.
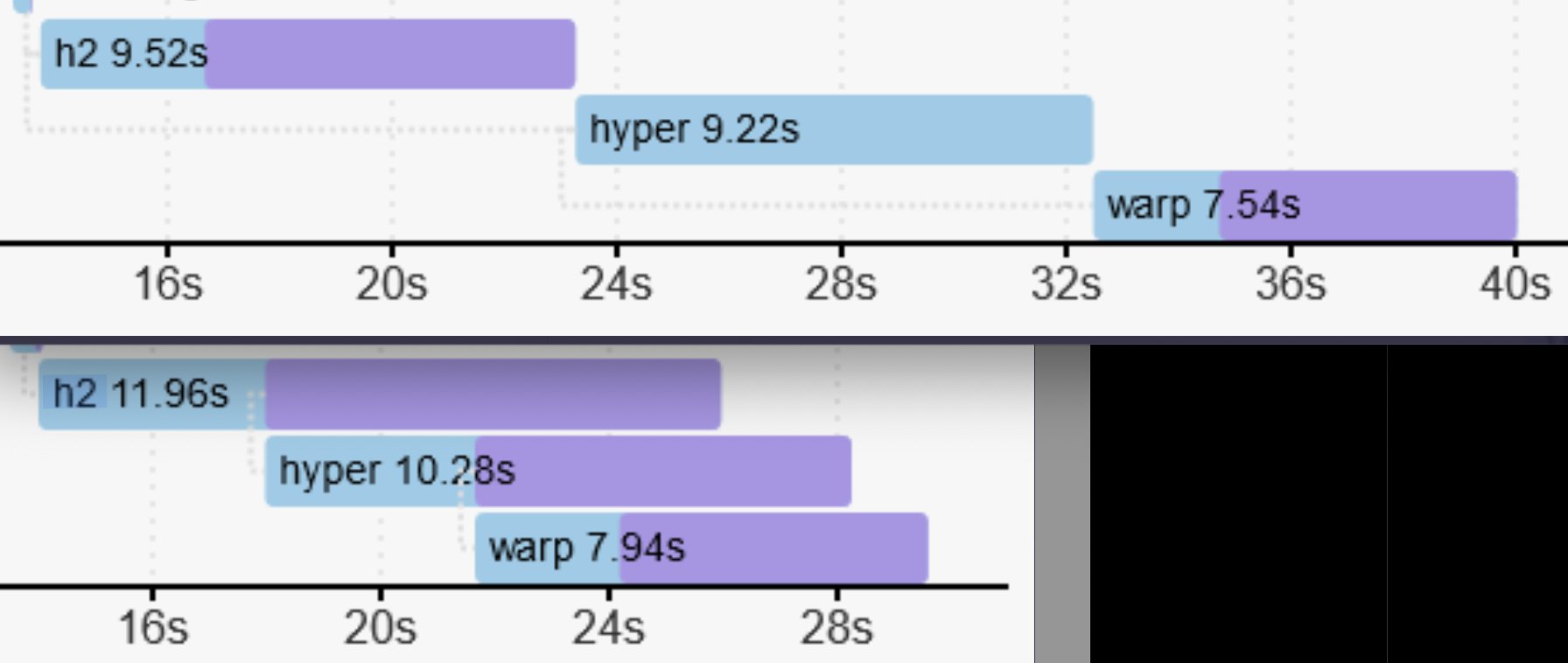
#2770: In this PR @lqd modified
the build configuration of the popular hyper crate so that the Rust compiler
could pipeline its compilation. The following image, generated with cargo
--timings, demonstrates the benefit. The top half shows how the hyper crate
used to build serially. The bottom half shows how it now parallelizes nicely,
shaving about 10 seconds off the build time for this example.
Finally, people love reading about failed optimization attempts, so here is one. The compiler currently uses LEB128 compression when writing integers to metadata. I looked into some alternative schemes for compressing integers, but was not able to do anything useful. These schemes are generally designed for sequences of integers that are all the same size, but Rust metadata interleaves integers of varying sizes, preventing their use.
General progress
For the period 2022-02-25 to
2022-04-12
it’s hard to do my usual progress report. This is because every primary
benchmark except helloworld was upgraded since last time and thus lacks a
comparison for this period.
Among the secondary benchmarks, the largest changes are improvements, but there
are more regressions than improvements. A lot of the larger regressions are for
doc builds due to the recently merged
#95515. These should be fixed
by #95968.
Because of all that, I won’t draw any firm conclusions. This is unsatisfying, but we’ll have much better data next time around with the new benchmarks. Plus the scope of the work over the past two months has been broader than usual, with many real improvements that fall outside the scope of what’s measured by rustc-perf. This is not a bad thing! rustc-perf is important, but it’s never going to measure everything, and it shouldn’t be the only focus.
What’s next?
Having finished with declarative macros for now, I’m planning to do a deep dive into the compile time performance of procedural macros. Let me know if you have any insights or data points relating to this.
More generally, if anyone is interested in helping out with Rust compiler
performance, check out this Zulip
thread
in the t-compiler/performance stream, which identifies small tasks that are
suitable for new contributors. Questions are welcome.
Thanks for reading! That was a long one. Everyone who made it this far gets a gold star: ⭐