Back-end parallelism in the Rust compiler
This post describes some performance work I have been doing recently on rustc. I spent several weeks on a particular problem with only a small amount of success. I hope a write-up will be interesting and educational, and may even lead to suggestions that make things better. The post is aimed at readers with some familiarity with compilers.
Codegen Units
rustc compiles Rust code down to a representation called MIR, and then performs code generation, converting the MIR into LLVM IR, which is then passed to LLVM, which generates machine code.
LLVM can provide coarse-grained parallelism by processing multiple chunks of LLVM IR in parallel. rustc uses this to speed up Rust compilation. We call one of these chunks a codegen unit (CGU).
Non-incremental builds
In a non-incremental build rustc splits the code by default into up to 16 CGUs.
Consider this screenshot from a samply
profile of rustc compiling the image-0.24.1 crate:
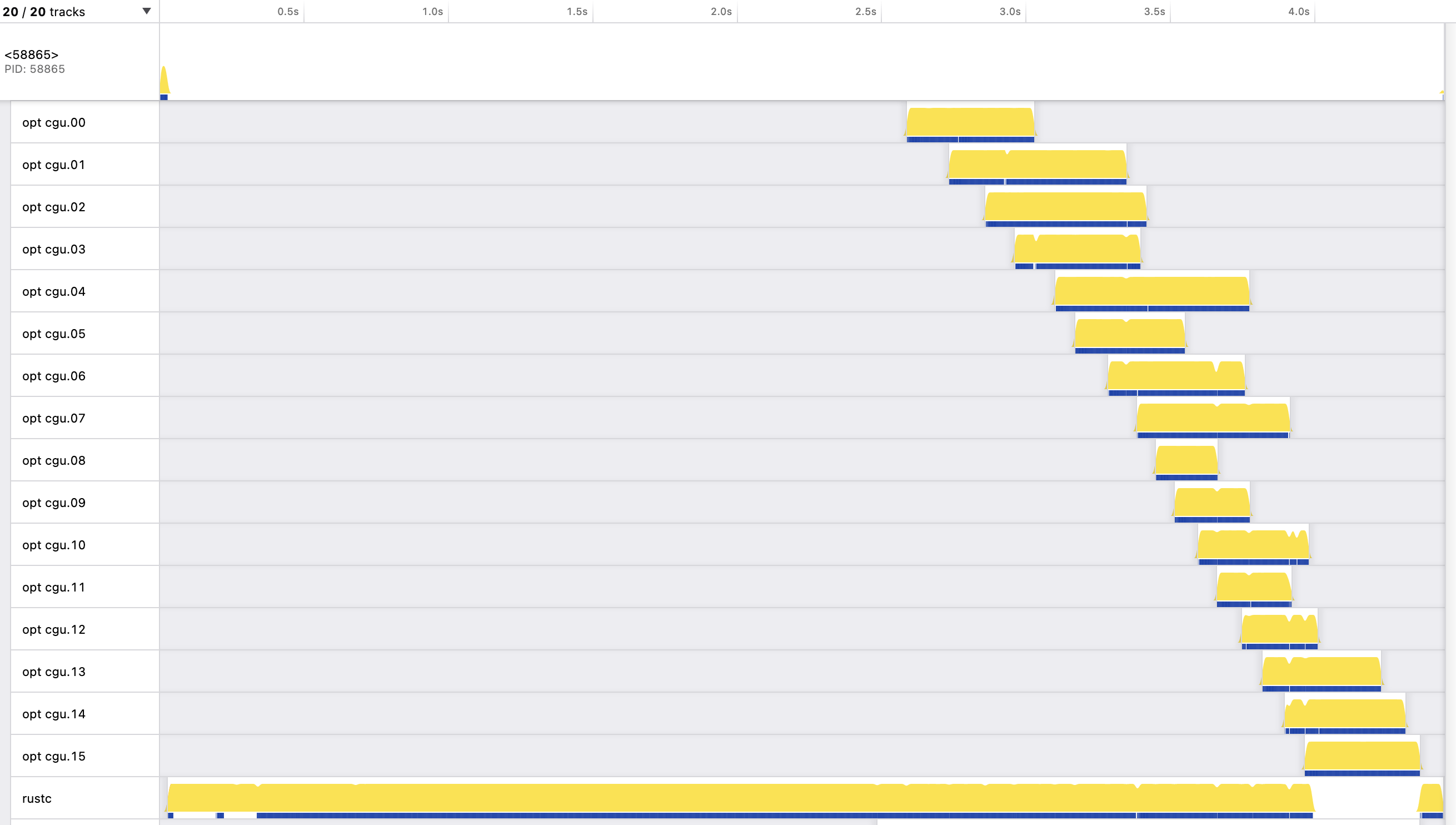
Time is on the x-axis, and each horizontal line represents a thread. The main
thread is shown at the top, labelled with the PID. It is active at the start
just long enough to spawn another thread labelled rustc. The rustc thread,
shown at the bottom, is active for most of the execution. There are also 16
LLVM threads labelled opt cgu.00 through to opt cgu.15, each one active for
a short period of time.
The period of execution involving the LLVM threads can be considered the back-end, which is parallel. Everything before that is the front-end. There is a parallel front-end under development, but rustc’s current front-end is completely serial.
The staircase shape formed by the left-hand side of the LLVM threads is because
the rustc thread does the MIR-to-LLVM-IR conversion one CGU at a time, and the
LLVM thread for a CGU cannot be spawned until that conversion is complete. The
LLVM threads run for varying lengths of time. (More about that later.) The
rustc thread is active the entire time except a short stretch near the end,
when it has finished producing LLVM IR for all the CGUs and is waiting for the
last few LLVM threads to finish; it then does a small amount of work at the
very end.
A decent amount of parallel execution is evident in the second half, with a
peak of around seven threads active at the same time. If those LLVM threads
instead had to execute serially it would take a lot longer. In fact, we can
observe this by setting the
codegen-units
value to 1 in Cargo.toml, which results in this profile:

In this case there is a single LLVM thread. When it runs the rustc thread is
inactive. (The main thread is blank in this screenshot. I think this is because
no samples were taken during its short period of activity.)
Execution with a single CGU is fully serial and takes 9.7s, more than twice the 4.5s for the earlier run. A big difference! But the speed from parallelism comes at a cost.
- Splitting and recombining the CGUs takes a certain amount of work, so the number of cycles executed is higher, as is the energy use.
- Peak memory usage is higher.
- The compiled binary is larger and the code quality is lower, because LLVM does a worse job when processing code chunks in isolation, instead of all at once.
For many people the first two items won’t matter much, and for debug builds the last item might also not matter much. But for release builds the lower code quality is a big deal. Enough so that in release builds rustc gets LLVM to perform a subsequent step called “thin local LTO” that greatly improves the code quality. Here is a profile for a release build of the same crate:

I had to zoom out in Firefox to fit the entire profile into a single
screenshot. The left two thirds is similar to the debug profile, but the right
third shows sixteen additional threads labelled lto cgu.00 through to lto
cgu.15. These are the thin local LTO threads. They can’t start until all the
opt threads are finished, but then they can all start at the same time
because the rustc thread doesn’t need to do any extra work. So we get 16
threads active in parallel for part of that period.
Setting codegen-units to 1 gives even better code quality than thin local
LTO, but takes longer. Some authors of binary rust crates always use that
setting for release builds because they are willing to accept the
extra compile times for the highest code quality.
Finally, note that rustc uses the
jobserver crate to rate-limit
the spawning of threads so it won’t overload the machine. This is important
when you are building a large project with Cargo and multiple rustc processes
are compiling different crates at the same time.
Incremental builds
Incremental builds use much smaller CGUs, up to 256 by default. This is because if anything about a CGU has changed since the previous compilation, LLVM must reprocess the entire CGU. So we want fine-grained CGUs to minimize the amount of work LLVM must do when small changes are made to the code. This compromises code quality, but incremental builds are only used by default for debug builds, where code quality is less important.
I won’t show a profile of an incremental build because it is hard to get a good screenshot showing hundreds very short-running threads, but you can probably imagine what it looks like.
Instead of spawning one thread per CGU in this case, rustc could instead spawn a smaller number of threads and reuse each one for multiple CGUs. This is probably a good idea, though the current structure of the code makes it easier to spawn a thread for every CGU.
CGU formation
So how are these CGUs actually formed?
Roughly speaking, a Rust program consists of many functions, which form a directed graph, where a call from one function to another constitutes an edge. We need to split this graph into pieces (CGUs), which is a graph partition problem. We want to create CGUs that are roughly equal in size (so they take about the same length of time for LLVM to process), and also minimize the number of edges between them (because that makes LLVM’s job easier and results in better code quality).
Actually, because of the staircase effect we saw above, we don’t want the CGUs to be exactly the same size. The ideal case would be if there was a slight gradient in CGU size that matched the staircase gradient. That way, all CGUs would finish processing at exactly the same time, for maximum parallelization.
Graph partitioning is an NP-hard problem. There are several common algorithms which are moderately complex to implement. rustc instead does something much simpler. It starts by simply creating one CGU per Rust module: every function in a module is put into the same CGU. Then, if the numbers of CGUs exceeds the limit (by default 16 for non-incremental builds and 256 for incremental builds) it repeatedly merges the two smallest CGUs until the limit is reached. This approach is simple, fast, and takes advantage of domain-specific knowledge in a useful way—program modules tend to provide good natural boundaries.
All this relies on a way to measure CGU size. Currently we use the number of MIR statements in the CGU to estimate how long it will take LLVM to process the CGU. (More on this later.)
There is a large design space here, with many other possible ways of forming and ordering CGUs. The next section will explore some of the alternative approaches that I tried.
What I tried
The number of CGUs (part 1)
The first thing I tried was changing the default number of CGUs for non-incremental builds from 16, but 16 seemed like something of a local optimum.
#111666: I then tried reducing the default number of CGUs for incremental builds from 256 to 128 and 64. This gave significant improvement to speed and binary size for two kinds of incremental builds: building the first time, and rebuilding with no changes. But for incremental rebuilds involving small code changes there were a few cases where compilation was 4-10x slower! It turns out more coarse-grained CGUs means that when things change, LLVM needs to do more work. This won’t be surprising to anyone who has read the previous section, but at this early point it was a surprise to me. So I closed this PR, leaving the default at 256.
CGU merging (part 1)
#111712: Next I tried improving the CGU merging algorithm. The goal when merging is to create CGUs that are similar in size, which is a multiway number partitioning problem. Currently rustc repeatedly merges the two smallest CGUs until the number of CGUs is low enough. This is actually a really bad algorithm! An analogy: when filling the trunk of a car with many items you should place the largest items first, because they are the hardest to place, and place the smallest items last, because they are the easiest to place and can fit in the remaining gaps. The same intuition applies to CGU merging: repeatedly merging the smallest CGUs is exactly the wrong thing to do.
For example, here are the CGU sizes for a release build of cargo-0.60.0,
which is a large crate: 314620, 186393, 175303, 159304, 154652, 150888, 143173,
141119, 134430, 129427, 127643, 121790, 116463, 109474, 109074, 100381. The
average size is 148383, but you can see there is quite a spread around that.
#111712: So I tried changing rustc to repeatedly merge the Nth and (N+1)th largest CGUs, where the largest CGU has an index of 1, and N is the CGU limit. The intuition here is that when you have more than N CGUs, at least one of the N biggest CGUs will need to grow. So we pick the smallest of the largest N CGUs (i.e. the Nth CGU) as the merge destination because it has the most room for growth. Then we pick the largest of the remaining CGUs (i.e. the (N+1)th CGU) as the merge source because it’s the hardest to place. This algorithm is as simple as repeatedly merging the two smallest CGUs, but it gives much better results as measured by the spread of the resulting CGU sizes. Unfortunately, it made actual compile times, memory usage, and binary sizes all marginally worse, which was a surprise. So I closed this PR as well.
CGU splitting
#111900: At this point I thought I understood why the better merging algorithm gave bad results: compilation time would be dominated by the largest CGU, and better merging usually doesn’t affect that CGU. So I tried splitting the largest CGUs and further tweaking how merging works. The performance results were absolutely terrible, which was a strong indication that (a) module boundaries are worth respecting, and (b) my hypothesis was wrong.
CGU processing order
#111937: I then tried a minor change to the CGU processing order, which had negligible effect.
An aside: the profiles above show execution when we compile the CGUs in order from largest estimated size to smallest. In practice, rustc does something slightly different: it does the largest, then the smallest, then the second largest, then the second smallest, and so on. This was found in the past to slightly reduce peak memory usage without affecting speed. But for the profiles in this blog post I modified the compiler to use the largest-to-smallest order because that gives profiles that are easier to understand.
CGU formation
#112093: I then thought that
it might help to “massage” the CGUs a little before merging, by moving
functions from one CGU to another in some cases. For example, if a leaf
function (i.e. one that doesn’t call any other functions) called f in CGU A has a
single caller g in CGU B, then it makes sense to move f from A to B, thus
removing an inter-CGU edge. (There are other similar cases involving non-leaf
functions that make sense to move as well). I implemented this and it gave some
moderate improvements, but I am currently undecided whether it is worth the
extra complexity.
While implementing this I also spent some time visualizing the call graphs. I started with GraphViz. The graphs looked nice for very small programs, but for larger programs they rapidly became impossible to read and navigate. I complained about this on Mastodon and got a suggestion to use d2, which is slower but gives somewhat more readable graphs. Here is the graph for a toy program prior to massaging, with nine CGUs:

Here is the graph for the same program after massaging, where it has dropped to five CGUs.

Unfortunately the layout is quite different, which complicates comparisons to the first graph.
And here is the graph for serde-1.0.136 after massaging:

Even though serde is only moderately-sized, this graph is at the outer limit
of what is readable in a browser with SVG output.
I am aware of tools such as Gephi and igraph that are designed to handle very large graphs, but I couldn’t find one that could handle nested graphs, which I needed for the CGUs. The state of the art in call graph visualization seems grossly underpowered. Maybe I’m overlooking something?
Inlining
One thing I haven’t mentioned until now is that inlined functions are treated differently to non-inlined (root) functions. Each root function is placed in exactly one CGU, but any inlined function is placed in every CGU that contains a root function that the inlined function is reachable from. LLVM requires this, and it means inlined functions can be duplicated in multiple CGUs.
Furthermore, the placement of inlined functions happens after the placement of root functions. Which makes sense. What makes less sense is that CGU merging occurred before inline function placement. Which means that the size estimation that guides CGU merging didn’t take inlined functions into account. Which is a big deal, especially for release builds, where inlined functions are very common.
#112375: So I did the obvious thing and moved inlining before CGU merging. Surely this would give better results, because the size estimates would be better? Alas, no. Once again, the performance results were no better, perhaps marginally worse.
#112695: Later on this problem was confounding some additional attempts to improve the size estimates (more on that later) so I ended up doing it anyway. It did make the code slightly simpler.
The number of CGUs (part 2)
#112441: Earlier I tried reducing the maximum number of CGUs for incremental builds from 256 to 128 and 64, and found that this sometimes gave bad results when rebuilding after small changes because larger CGUs needed to be redone. Then I thought of doing the opposite, i.e. removing the upper limit on CGUs altogether for incremental builds. In practice, the 256 limit is only reached for quite large crates. Which means the limit artificially reduces the effectiveness of incremental compilation for these large crates. And for no obvious benefit, other than avoiding a large number of threads.
At the time of writing, this PR is still open and in an uncertain state.
A minimum CGU size
At this point one thing was clear: having fewer CGUs results in smaller binaries, better code quality, and less memory usage, at the cost of sometimes increasing compile times. However, when a CGU is very small the speed gained from parallelism is correspondingly very small, or even zero, due to there being some overhead in creating a CGU and starting a new thread.
#112448: So I tried introducing a minimum CGU size and it gave good results. Finally, a success! Good improvements on memory use, binary size, and cycles, and roughly neutral results on walltimes. This change mostly benefits small crates, sometimes reducing the number of CGUs to one. In contrast, large crates are likely to have CGUs that all naturally exceed the minimum threshold.
CGU merging (part 2)
#112648: The previous PR’s success showed that reducing the number of CGUs can be a clear win in some cases. So I tried a related idea: be more aggressive about merging CGUs for non-incremental builds—going beyond what was required for both the CGU count limit and the minimum CGU size—so long as the resulting CGUs don’t become bigger than the biggest existing CGU. But the performance results were poor, largely because the size estimates are sometimes poor, as the next section will describe.
Better size estimates
At this point I realized a major problem: the CGU size estimates just aren’t very good. Both overestimates and underestimates are common, and factors of two or more aren’t unusual. E.g. the compiler might estimate two CGUs as being the same size, but one might take twice as long as the other for LLVM to process.
For example, consider this profile of a debug build of regex-1.5.5:
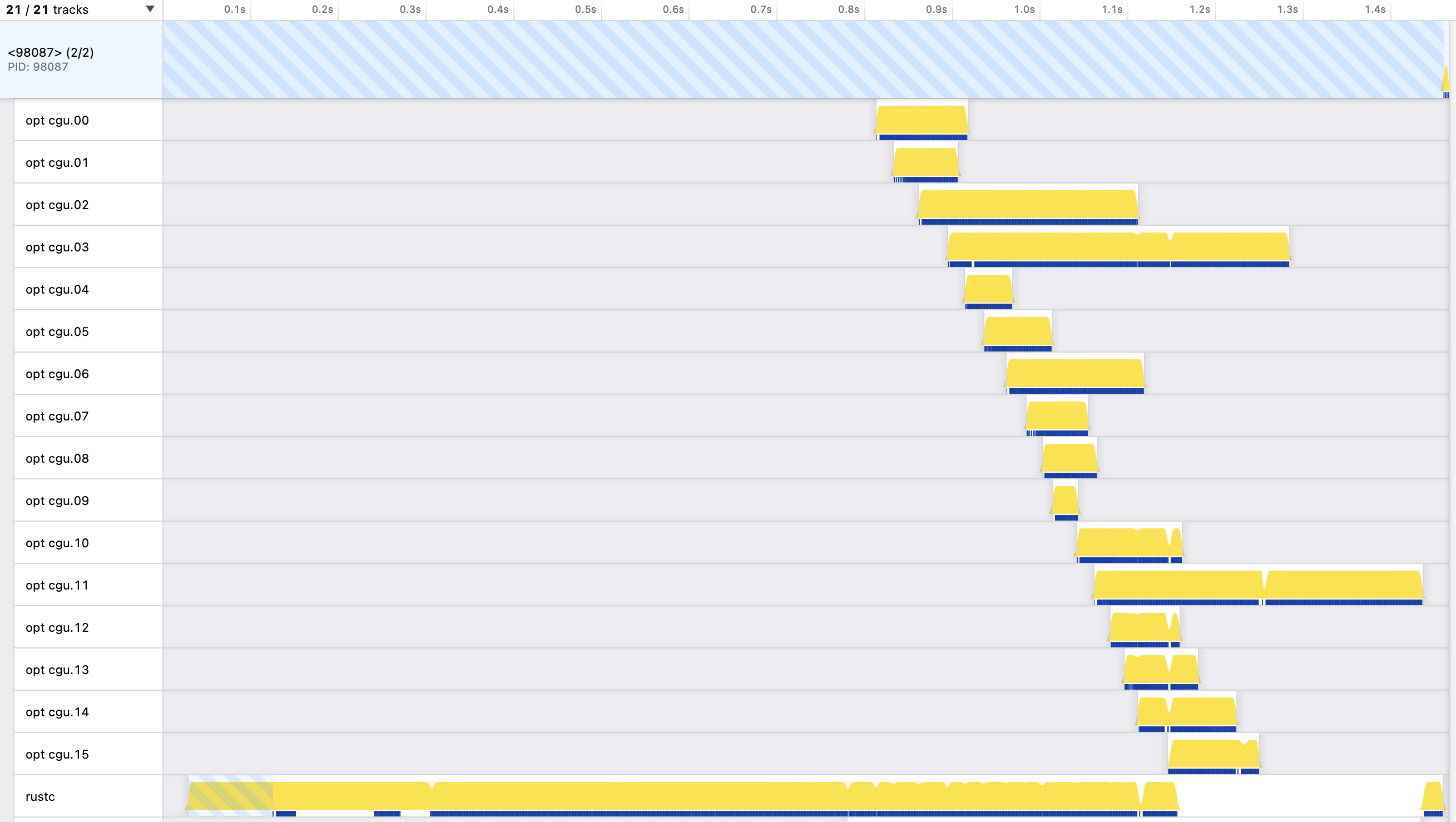
Moving from top to bottom we would hope that the LLVM thread durations get smaller, but this is far from true. CGUs 03 and 11 are particularly badly underestimated, and we end up waiting for their threads long after all the others have finished.
I think this explains why a lot of my previous attempts didn’t improve anything. For example, there’s no point introducing clever merging algorithms if the CGU sizes directing the merging are inaccurate. This inaccuracy effectively smothers the entire CGU formation process in a thick layer of randomness, which makes it hard to improve.
So I decided to quantify the size estimate error. I compared the CGU size estimates against the actual time taken by LLVM to process the CGUs, and came up with a measure of the error based on the mean absolute deviation.
(An aside: when measuring forecasting errors, normally you forecast an amount using a particular metric, and then you measure the outcome with the same metric, and then compute the error using the difference. But CGU size estimates are different. They don’t predict in absolute terms, such as milliseconds, how long a CGU will take to compile. Instead, they are effectively a relative measure. A single CGU size estimate is little use in isolation; it only becomes useful in relation to one or more other CGU size estimates. This means many common measures of error such as mean-squared can’t be used.)
This gave me a measure of error for the CGU size estimates, which meant I could try other estimation functions for comparison. But how to improve the estimation? It’s very difficult to accurately estimate how long a chunk of code will take to compile. There are many possible characteristics of the code that could affect things. As I mentioned earlier, currently the estimate is based on the number of MIR statements in the CGU. I thought that the number of functions might also be relevant—e.g. lots of small functions might be faster or slower to process than a few large functions—but I couldn’t find a better estimation function that way. (I did find a few that gave obviously worse results, though!)
#113407: Then I tried an estimation function that uses the number of basic blocks. This gave much lower errors than estimating based on the number of statements. Which makes a certain amount of sense, given that basic blocks are straight-line code that are fairly easy for compilers to process, and it’s the control flow represented by edges between basic blocks that cause a lot of the complexity. I was hopeful at this point, but the performance results were underwhelming, and it’s not clear that the change is worth merging. Yet again.
This was disappointing. I think the problem is that even with better estimates
on average, it just takes one bad estimate to mess things up. Particularly if
the bad estimate is an underestimate, as we saw with regex-1.5.5 above.
Imagine if the compiler produced 16 CGUs all with the same size estimate, and
15 of them took the same amount of time while one of them took twice as long.
That slow one would be the “long pole” that messes everything up.
In fact, this might explain why some of my earlier attempts at improved merging algorithms gave poor results. The current sub-optimal merging algorithm results in CGUs with a range of size estimates, some larger, some smaller. That unevenness can accommodate moderate underestimates for all of the CGUs except for the largest one or two. In contrast, if all the CGUs are the same size, the situation is more brittle, and an underestimate for any CGU could mess things up.
Ultimately, I think the inaccuracy of the size estimates is the limiting factor for this entire CGU formation problem. If we had perfect size estimates we could do things a lot better. Throwing machine learning at the estimation problem is a possibility, but I fear that it would still be difficult to come up with an estimation function that is (a) comprehensible and (b) accurate across many different machines. Despite my experiments, it’s not clear to me what characteristics of the MIR code should even be considered by the estimation function. Also, there are two other experimental rustc back-ends (one using Cranelift, and one using GCC) and it’s not clear if an estimation function that works well for LLVM would also work well for them.
Another idea is to record the actual time taken per CGU and use that to guide future estimates. But this would introduce a large source of non-determinism into compilation. Imagine doing a release build of a Rust program twice in a row on a single machine, or on two different machines, and getting different binaries each time? It would be the exact opposite of reproducible builds.
The number of CGUs (part 3)
Just before publishing this post, I tried one final thing based on a question from Jakub Beránek:
I wonder if we oversubscribe though - do we still generate 16 threads in parallel if you only have 2 cores?
The answer to this question is “yes”. rustc doesn’t consider the number of cores when choosing the CGU limit.
#113555: So I tried a simple
change to limit the number of CGUs for non-incremental builds to the number of
machine cores. For example, the CI machine we use for performance evaluation
has 12 cores, so the maximum number of CGUs would be 12 instead of 16. This
change gave great results for cycle counts and binary size, as expected. But it
greatly increased walltimes and maximum memory use for some benchmarks, which
was a surprise. I think the walltime result might be explained by the staircase
effect we saw above: with 12 cores and 16 CGUs we actually don’t oversubscribe.
rustc never gets more than seven or eight LLVM opt threads running in
parallel (e.g. the first LLVM opt thread finishes well before the 12th can
start) so we get the usual “fewer, larger CGUs result in longer walltimes”
result. On a machine with just two or four cores we probably do oversubscribe
and so this change might be more beneficial.
Other improvements
Even though my efforts were mostly unsuccessful, performance-wise, there were some other benefits. First, I did a lot of refactoring and code cleanups while trying things out, in #111899, #112053, #112128, #112162, #112369, #112639, #112827, #112830, #112913, and #113390.
I also improved the debugging output that rustc can produce about CGUs, which is useful for both debugging and profiling purposes, in #111743, #112155, and #112946.
Conclusion
This is a real tar pit of a problem. The use of CGUs involves many trade-offs between compile speed, memory use, energy use, binary size, and code quality. I tried many things, and most of them failed. In a lot of cases wins on one metric were balanced or outweighed by losses on another. The improvement-to-effort ratio on this one was really low. Performance tuning of parallel code can be really hard.
Thank you to Wesley Wiser for reviewing most of the mentioned PRs, and to Jakub Beránek and Rémy Rakic for providing comments on a draft version of this post.