How to speed up the Rust compiler in October 2022
It’s time to look at some of the progress on Rust compiler speed made since my last post in July.
Metrics
First, a note about metrics. The rustc benchmark suite uses several different time-related metrics, each of which has its pros and cons.
- Wall-time: this is the most realistic metric, because it exactly matches a user’s experience. But has high variance, which makes it poor for detecting small changes.
- Instruction counts (icounts): this is the least realistic metric. But it has very low variance, which makes it good for detecting small changes. It correlates fairly well with wall-time. You’d be mad to use it to compare the speed of two different programs, but it is very useful for comparing two slightly different versions of the same program, which are likely to have a similar instruction mix.
- Cycles: this is in the middle, in both realism and variance.
In this post I use a mix of these metrics: wall-time for cases where the performance changes are large, icounts where they are small, and cycles for intermediate cases. I try not to get too hung up on precision. This is a blog post, not a scientific paper.
Big improvements
Let’s start with the biggest improvements, which were the work of multiple people.
#101403: In this PR,
@bjorn3 and @Kobzol enabled link-time
optimization
(LTO)
on the rustc front-end (the part written in Rust, which excludes LLVM). This
gave a mean wall-time reduction of 3.74% across all benchmark results, and up to
10% on popular real-world crates like diesel, libc, and serde. A big
improvement! Enabling LTO on Windows and Mac is future work.
#94381: BOLT is a post-link optimizer that rearranges code layout based on profiling data. It’s similar to PGO, but works on the compiled binary rather than the compiler’s internal representation. In this PR @Kobzol got BOLT working for our builds of LLVM on Linux. The PR was opened in February, but it took a long time to finish because earlier versions of BOLT would often crash. The PR gave a mean cycles reduction of 0.83% across all benchmark results, and 1.57% across all optimized build benchmark results, with the highest being 6%. It also gave a mean max-rss (peak memory) reduction of 3.61% across all benchmark results, and a 3.5% reduction in compiler bootstrap time. This was an item on the 2022 roadmap. BOLT is currently Linux-only so these improvements aren’t available on Windows or Mac.
(Note: if you want to understand the use of PGO/LTO/BOLT across different platforms, the new tracking issue will be of interest.)
#99464: In this PR @nikic upgraded the version of LLVM used by rustc to LLVM 15. This gave a mean cycles reduction of 0.49% across all benchmark results, and 1.57% across all optimized build benchmark results, with a few in the 5-20% range. It is excellent to see Rust benefiting from the hard work done by LLVM developers.
#11032 (cargo): In this PR @lqd adjusted Cargo’s crate compilation ordering algorithm to improve available parallelism. This kind of change is never a pure win, but the detailed experiments showed clearly that it’s a win more often than a loss, that the wins are larger than the losses, and the wall-time reductions of from-scratch builds sometimes exceed 10%. This was another item on the 2022 roadmap.
#100209: In this PR,
@cjgillot made metadata decoding lazier, giving
a mean cycles reduction of 0.67% across all benchmark results, and 1.29%
across all check build benchmark results.
Runtime benchmarking
rustc-perf has long been used for compile-time benchmarking, i.e. measuring the speed of the compiler. @Kobzol is now in the process of extending it to support runtime benchmarking, i.e. measuring the speed of the programs generated by the compiler. There was a project called lolbench that did this in the past, but it has been defunct for some time, so this new work will fill an important gap.
The runtime benchmark suite and harness are still in preliminary stages. There are currently only three benchmarks and the harness only prints text results, without any storage of results or comparison tools. But it’s a good start. For more details, consult the planning document.
AST/HIR/THIR shrinkage
The Zig developers once described how they got good speed wins by optimizing the Zig compiler’s IR data structures for size, reducing memory traffic and cache pressure. Inspired by this I tried doing similar things for Rust, with mixed success.
#100999: In this PR I shrank
two types that are used a lot: FnAbi (from 248 bytes to 80 bytes) and
ArgAbi (from 208 bytes to 56 bytes). This didn’t affect speed much, but did
reduce peak memory usage on some real-world crates by up to 7%.
#100441: In this PR I
shrank the AST’s Attribute type from 152 bytes to 32 bytes, giving a max-rss
reduction of 5.13% across all rustdoc benchmark results.
#100994: In this PR I shrank
the thir::Expr type. This reduced the max-rss for the expression-heavy
deep-vector stress test by up to 15%, though it didn’t affect much else.
Those were the changes that were clear wins. I also tried plenty of other stuff, involving types like: MacCall, AttrVec, thir::Pat, PredicateS, hir::Ty and hir::Pat, and hir::def::Res. All of these PRs shrank frequently-instantiated types, but none of them had much effect on performance.
I also replaced rustc’s
inefficient home-grown ThinVec type with the more sophisticated one from
thin_vec. This seemed like it should
have been a slam dunk and an easy performance win but it took several changes
to thin_vec
(#32,
#33,
#34) just to get it working and
to performance parity. Plus, my attempts to use ThinVec more widely
didn’t help performance.
I do still have one ongoing attempt, shrinking
ast::Expr, which is one of
the most frequently instantiated types. It’s facing a slightly tortuous path
to review acceptance, but even it only gets moderate wins.
To support all of the above, I also improved the measurements of the done by
-Zhir-stats for the AST and
HIR.
Overall this avenue of exploration has been frustrating, with a lot of effort
yielding just a few minor wins. I haven’t taken things nearly as far as the Zig
developers, but I was hoping that some type size reductions of important types
would still yield small but clear performance improvements. Perhaps there’s a
magic threshold where the speed wins kick in? E.g. for ast::Expr going from
104 bytes to 88 bytes made little
difference, but then shrinking
to 72 bytes got the small wins I mentioned above. Would 64 bytes be noticeably
better? Possibly—that’s the size of a cache line—but it might require as much
effort as going from 104 to 72. Would 32 bytes be noticeably better? Almost
certainly, but that would require some heroic efforts. Also, aggressive type
compaction can compromise code readability. I’d love to be proven wrong, but it
doesn’t feel like this work is taking place in a good part of the
effort/benefit curve.
Miscellaneous speedups
#98655: In my last
post
I described how I improved the code generated for derived builtin traits. This
PR was a final change from that work that took a while to be merged. It avoids
generating the ne method for a derived PartialEq impl, because the default
impl (which is just the inverse of eq) is always sufficient. This gave a mean
icount reduction of 0.36% across all benchmark results, and up to 9% on some
extreme cases.
#99884, #102302: In these PRs I made did lots of tiny cleanups and performance tweaks in the lexer, in both cases giving a small icount reductions across many benchmark results, mostly sub-1%.
#98 (minifier-rs): In this PR I avoided some quadratic behaviour when removing tokens from a vector, and in #100624 @GuillaumeGomez imported an updated version of minifier-rs into rustdoc. This gave a mean icount reduction of 0.79% across all rustdoc benchmark results, and up to 9% on some extreme cases.
#102387: In this PR I inlined a few hot functions for small icount reductions across many benchmark results, mostly sub-1%.
#102692: In this PR I
optimized how token streams are concatenated, for up to 9% icount reductions on
the token-stream-stress stress test, and some sub-1% icount reductions on
cargo-0.60.0.
Performance tracking
Every time a new PR (or rollup of several PRs) is merged into the main Rust repository the compile-time benchmarks are run and the results are auto-posted as a comment in the PR. This lets PR authors know immediately if their change caused a performance improvement or regression, which is good. But the comments could to be hard to interpret for PR authors who aren’t intimately familiar with the benchmark suite.
In several PRs (#1369, #1386, #1388, #1415, #1416) I improved the content and layout of these comments. Compare an older comment with a newer comment.
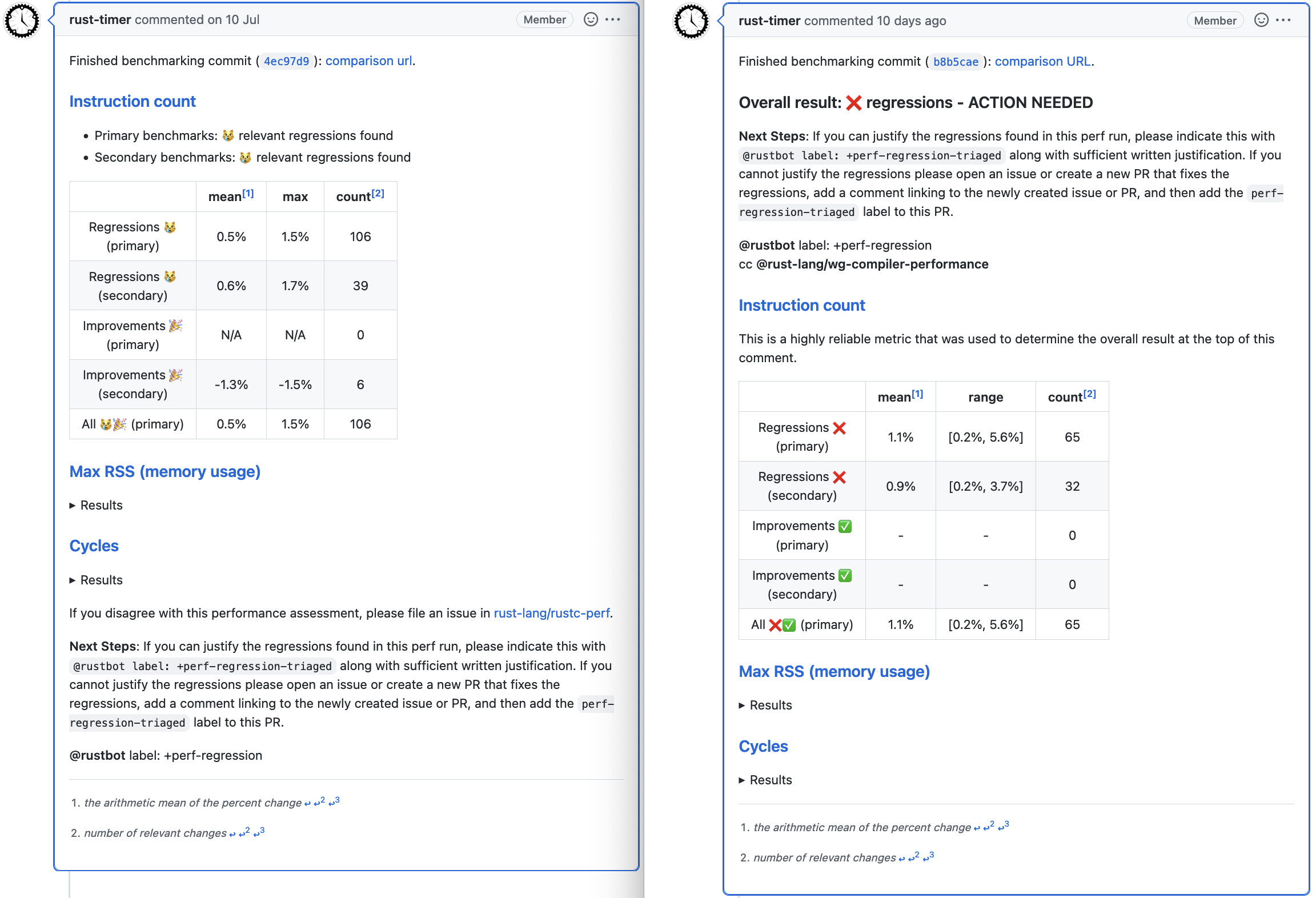
There are numerous improvements.
- There’s a clear overall result at the top, followed immediately by the “Next steps” instructions.
- The less important stuff is towards the bottom.
- There’s a brief description of each metric and how it is used. (Max RSS and Cycles are still folded by default.)
- The emoji used are clearer.
- Uninteresting table cells use ‘-‘, which is visually smaller than ‘N/A’.
- The table shows ranges for each line, instead of just the max.
I am no graphic designer, and this stuff is highly bike-sheddable. But I find the new form much easier to read, and I hope PR authors do too.
Equally importantly, the @rust-lang/wg-compiler-performance group is now CC’d to all merged PRs that regress performance. This results in quicker responses and eases the load on the people doing the weekly performance triage.
It’s also useful because sometimes the results are spurious, due to noise. Over the past few months we’ve had quite a few benchmarks go in and out of bimodal behaviour, bouncing between two different sets of results where icounts (the most stable metric) differ by 1 or 2%. It’s not clear why this occurs; my guess is that a hot path gets on a knife’s edge between two states, e.g. whether or not a particular function is inlined, or whether a register is spilled, and tiny changes nearby can cause flipping between these two states.
This can lead to confusing results for PR authors, who might be told that their change caused a regression or improvement that isn’t real. The benchmark suite does take variance into account when deciding whether a result is significant, but if a benchmark suddenly flips into a bimodal state it can take a while for its significance threshold to adjust. In the meantime, the CC means that rustc-perf experts can quickly identify such cases.
Finally, @Mark-Simulacrum did some experiments with the settings on the machine that does the CI performance runs, and found that disabling hyperthreading and turbo boost reduces variance significantly. So we have switched those off for good now. This increases the time taken for each run by about 10%, which we decided was a good tradeoff.
Cleanups
I like doing cleanups. These are generally small (or large) changes that make code simpler and/or shorter. I did a lot of these in recent months.
#101841: In this PR, which has
not yet been merged, I removed the code for the -Zsave-analysis option. This
unstable option has been a candidate for removal for a long time. It’s used by
some code analysis tools. The most notable of these was RLS, which has now been
officially
deprecated in
favour of rust-analyzer. The exact timing of the removal of
-Zsave-analysis has not yet been decided by the compiler team, though it’s
likely to be within a few months.
#102769: In this PR I cleaned up rustc’s startup code a bit, and rustdoc’s startup code even more. In particular, on one code path rustdoc would create and initialize some global data structures and a thread pool, and then shortly afterwards initialize a second set of the same global data structures and a second thread pool, and then never use first ones. Quoting from one of the commit messages:
rustdoc calls into
rustc_interfaceat three different levels. It’s a bit confused, and feels like code where functionality has been added by different people at different times without fully understanding how the globally accessible stuff is set up.
Beyond that, the cleanups were all small, but covered a wide range of areas:
lints,
token streams,
visitors,
visitors agains,
parsing,
AST and parser,
literals,
literals again,
attributes,
path segments,
attribute token streams,
FulfillProcessor,
token unescaping,
WhiteTrue::check_expr,
lexing,
register_res,
removing -Ztime,
RunCompiler::emitter,
startup, and
codegen.
General Progress
For the period 2022-07-19 to 2022-10-25 we had some excellent results on wall-time measurements.
- Of the 521 results measured across 43 benchmarks, 343 were significantly improved, 7 were significantly worse, and the mean reduction across these results was 10.14%.
- If we include results below the significance threshold, 498 were improved, 23 were worse, and the mean reduction was 8.21%. Reductions on primary benchmarks (which are mostly real-world crates) were a little better on average than those on secondary benchmarks (which are mostly stress tests and microbenchmarks), 9.01% vs. 7.46%.
- For rust developers there was a reduction in bootstrap times of 7%. Note that this measurement is not as reliable as the benchmark changes because the compiler’s code has changed during that period, so it’s not quite an apples-to-apples comparison.
These measurements are done on Linux, so they include the LTO and BOLT improvements. Windows and Mac improvements will be less because the compiler isn’t built with those tools, but should still be significant. The Cargo scheduling improvements mentioned above also aren’t reflected in these results, because they only measure the compilation of individual crates.
This is a great result for the three month period. The compiler keeps getting faster, which is good news for everybody. Thanks to everybody who contributed!